En esta ocasión les quiero hablar de otra forma de convertir texto a vectores, esta es distinta a las que hemos visto previamente ya que nos da como resultado un vector por cada token y cada uno de estos vectores es un vector denso.
Esta vez les traigo no un post original, sino más bien una traducción de un artículo que me parece vale mucho la pena. El artículo original es de Jay Alammar y se llama The Illustrated Word2vec:
“Hay en todas las cosas un ritmo que es parte de nuestro universo. Hay simetría, elegancia y gracia… esas cualidades a las que se acoge el verdadero artista. Uno puede encontrar este ritmo en la sucesión de las estaciones, en la forma en que la arena modela una cresta, en las ramas de un arbusto creosota o en el diseño de sus hojas. Intentamos copiar este ritmo en nuestras vidas y en nuestra sociedad, buscando la medida y la cadencia que reconfortan. Y sin embargo, es posible ver un peligro en el descubrimiento de la perfección última. Está claro que el último esquema contiene en sí mismo su propia fijeza. En esta perfección, todo conduce hacia la muerte” ~ Frank Herbert. “Dune” (1965)
Encuentro la idea de embeddings* una de las más fascinantes dentro del aprendizaje automático. Si alguna vez has usado Siri, Google Assistant, Alexa o Google Translate, o inclusive un teléfono con teclado que predice tu siguiente palabra, entonces seguramente te has beneficiado de esta idea que se a convertido en la clave de los modelos de Procesamiento de Lenguaje Natural (NLP). En las últimas décadas ha existido mucho desarrollo respecto a usar embeddings para modelos neuronales (investigaciones recientes incluyen embeddings contextualizados que llevan a modelos vanguardistas como BERT o GPT2).
Word2vec es un método para crear embeddings de forma eficiente que ha existido desde 2013. pero además de su utilidad para la creación de estos embeddings, algunos de sus conceptos han sido exitosamente empleados para crear modelos de recomendación y para hacer sentido de datos secuenciales, inclusive en aplicaciones comerciales no relacionadas con lenguajes. Compañías como Airbnb, Alibaba, Spotify, y Anghami le han sacado provecho a esta brillante pieza del mundo del NLP y la están usando para potenciar una nueva clase de modelos de recomendación.
En este post, vamos a revisar el concepto de embeddings, y cómo es que se generan estos con la técnica de word2vec. Pero comencemos con un ejemplo para familiarizarnos con el uso de vectores para representar cosas. ¿Sabías que una lista de cinco números (es decir, un vector) puede representar mucho sobre tu personalidad?
Embeddings de personalidad: ¿cómo eres?
“Te doy el camaleón del desierto, cuya habilidad para mezclarse con el fondo te dice todo lo que necesitas saber sobre las raíces de la ecología y las bases de la identidad personal” ~ Hijos de Dune
En una escala de 0 a 100, ¿qué tan introvertido/extrovertido eres tu (donde 0 es introvertido, y 100 es extrovertido)? ¿alguna vez has tomado un test de personalidad como MBTI – o, mejor aún, una prueba del modelo de los cinco grandes? si no lo has hecho, este tipo de pruebas te hace una serie de preguntas y te califica en diferentes ejes, siendo la introversión o extraversión uno de ellos.
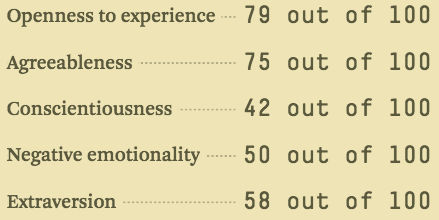
Imagina que obtuve 38/100 en el eje de introversión/extroversión. Lo podemos graficar así:

Si colocamos los valores de -1 a 1:

¿Qué tan bien crees conocer a una persona si sabes solo esta información sobre ella? No mucho, las personas son complejas. Añadamos otra dimensión, la calificación de otra de las características del test:
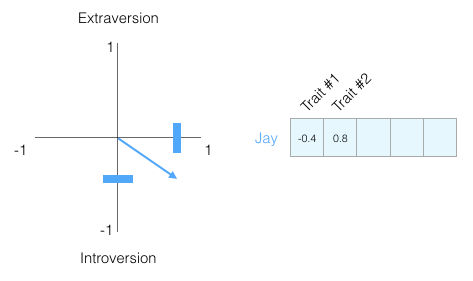
He ocultado qué características estamos graficando solamente para que nos acostumbremos a no saber qué representa cada dimensión – aun asi, estamos obteniendo mucha información de la representación vectorial de cada una de las personalidades.
Ahora podemos decir que este vector representa parcialmente mi personalidad. La usabilidad de esta representación es útil cuando quieres comparar otras dos personas conmigo. Digamos que me atropella un autobús y debo ser reemplazado por alguien con una personalidad similar. Dada la siguiente figura, ¿cuál de las dos personas es más similar a mi?
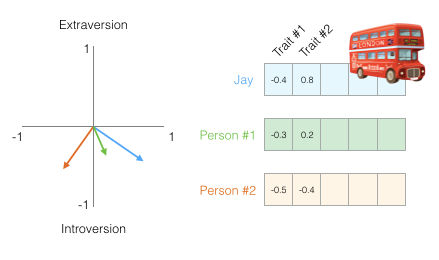
Cuando estamos trabajando con vectores, una forma común de calcular una medida de similitud es la similitud coseno (o cosine similarity que es su nombre en inglés).

Aun asi, dos dimensiones no son suficientes para capturar información suficiente sobre qué tan diferentes dos personas son. Décadas de investigación psicológica han llevado a que existen 5 características (y muchas sub-características). Así que vamos a usar todas en nuestras comparaciones:

El problema con estas cinco dimensiones es que hemos perdido la habilidad de graficar esas flechitas tan bonitas en dos dimensiones. Este es un obstáculo común en el aprendizaje automático en el que constantemente tenemos que pensar en espacios de grandes dimensiones. La ventaja que teneos es que la similitud coseno aún funciona sin importar las dimensiones:
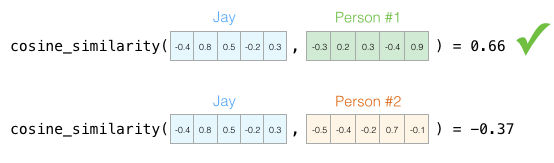
Para concluir esta sección, quiero que nos quedemos con dos ideas principales:
- Podemos representar personas (y cosas) como vectores de números (lo que es perfecto para las computadoras).
- Podemos comparar fácilmente qué tan similares son los vectores entre sí.

Embeddings de palabras
“El don de las palabras es el don del engaño y la ilusión” ~ Hijos de Dune
Entendiendo esto, podemos proceder a ver ejemplos de vectores-palabra entrenados (también conocidos como embeddings) y ver algunas de sus propiedades interesantes.
Este es un embedding para la palabra “king” –rey, en inglés– (GloVe vector entrenado en Wikipedia):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]Es una lista de 50 números. No podemos decir mucho si solamente vemos estos números.

Añadamos colores a las celdas basados en sus valores (rojo si están cerca de 2, blanco si están cerca de 0 y azul si están cerca de -2):

De ahora en adelante, vamos a ignorar los números y concentrarnos solo en los colores que indican los valores de las celdas. Comparemos “king” contra otras palabras:
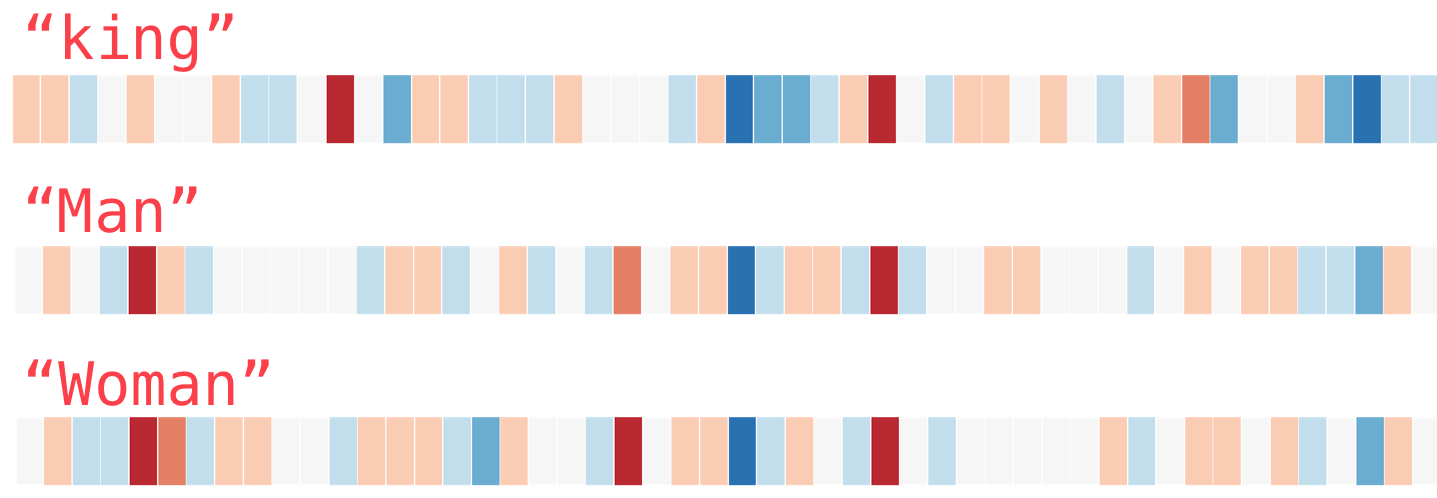
¿Ves cómo las palabras “man” y “woman” son más similares entre sí que cualquiera de ellas con “king”? Esto nos dice algo. Estas representaciones vectoriales capturan un poco la información/significado/asociaciones de estas palabras.
Aquí hay otros ejemplos (compara las columnas verticalmente, buscando columas con colores similares):
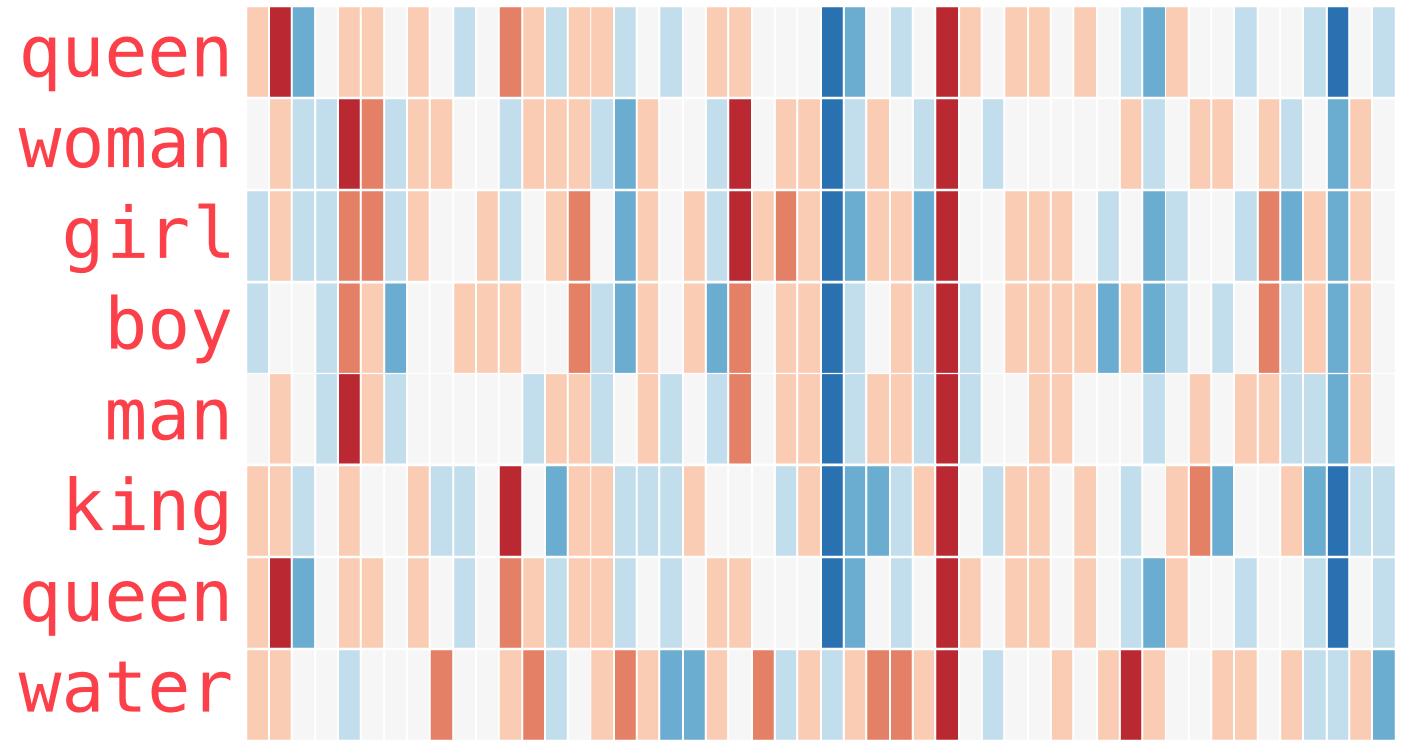
Algunas cosas para destacar:
- Hay una columna roja que coincide en todas las palabras. Las palabras son similares en esa dimensión (recuerda que no sabemos lo que significa cada dimensión).
- Puedes ver cómo “woman” y “girl” son similares en un montón de lugares. Lo mismo sucede con “man” y “boy”.
- “boy” y “girl” también tienen lugares en donde coinciden, pero son lugares diferentes a “woman” o “man”. ¿Será que estas estén codificando una vaga definición de juventud? es posible.
- Todas las palabras, excepto la última representan personas. Agregué, por ejemplo, un objeto (“water”) para mostrar las diferencias entre categorías. Por ejemplo, ¿ves esa columna azul fuerte a la derecha que se atenúa cuando llegamos al embedding de “water”?
- Hay otros lugares en donde “king” y “queen” son diferentes de todas las demás, ¿será que estas diferencias codifiquen un concepto vago de realeza?
Analogías
“Las palabras pueden llevar todo el peso que queramos. Todo lo que se requiere es un acuerdo tradición a partir de la cual construir” ~ Dios emperador de Dune
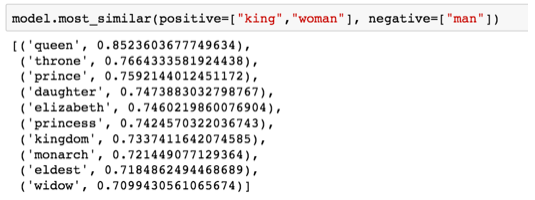
Los ejemplos más usados que muestran una de las características más increíbles de los embeddings es el concepto de analogías. Podemos sumar y restar embeddings y llegar a resultados interesantes. El ejemplo más famoso es la fórmula “king” - “man” + “woman”:
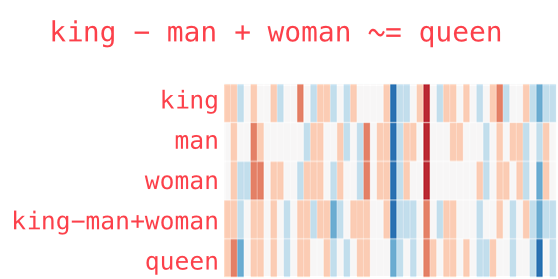
Podemos visualizar esta analogía como lo hemos hecho anteriormente:
Ahora que hemos revisado los embeddings, aprendamos más acerca del proceso para obtenerlos. Pero antes de que lleguemos a word2vec, necesitamos conocer a su padre conceptual: los modelos de lenguaje neuronales.
Modelando lenguajes
“El profeta no se distrae con ilusiones del pasado, presente y futuro. La fijeza del lenguaje determina tales distinciones lineales. Los profetas sostienen la llave de la cerradura en un idioma. Este no es un universo mecánico. La progresión lineal de los eventos la impone el observador. ¿Causa y efecto? No es eso para nada. El profeta pronuncia palabras fatídicas. Vislumbras algo “destinado a ocurrir” pero el instante profético libera algo de portento y poder infinitos. El universo sufre un cambio fantasmal” ~ Dios emperador de Dune
Si uno quisiera un ejemplo de una aplicación que usa NLP, uno de los mejores sería la predicción de la próxima palabra en el teclado de un teléfono. Es una característica que miles de millones de personas usan cientos de veces al día.
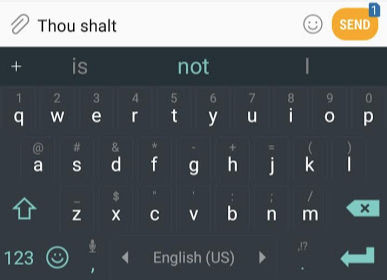
La predicción de la próxima palabra es una tarea que puede llevarse a cabo usando un modelo de lenguage (language model, en inglés). Un modelo de lenguaje puede tomar una lista de palabras (digamos, dos), y tratar de predecir cuál es la que le seguiría.
En la captura de pantalla de arriba, podemos pensar que el modelo tomó estas dos palabras en color verde (Thou, shalt) y regresa un conjunto de sugerencias (“not” es la que tenía la mayor probabilidad):

Puedes pensar en el modelo como una caja negra:

Pero en la práctica, el modelo no solamente regresa como resultado una sola palabra. En realidad, entrega las probabilidades para todas las palabras que “conoce” (el conjunto de todas las palabras que conoce se llama vocabulario, que pueden ir desde unas cuantas miles hasta millones de palabras). Es la responsabilidad del teclado encontrar las palabras con mayor probabilidad y presentarlas al usuario.
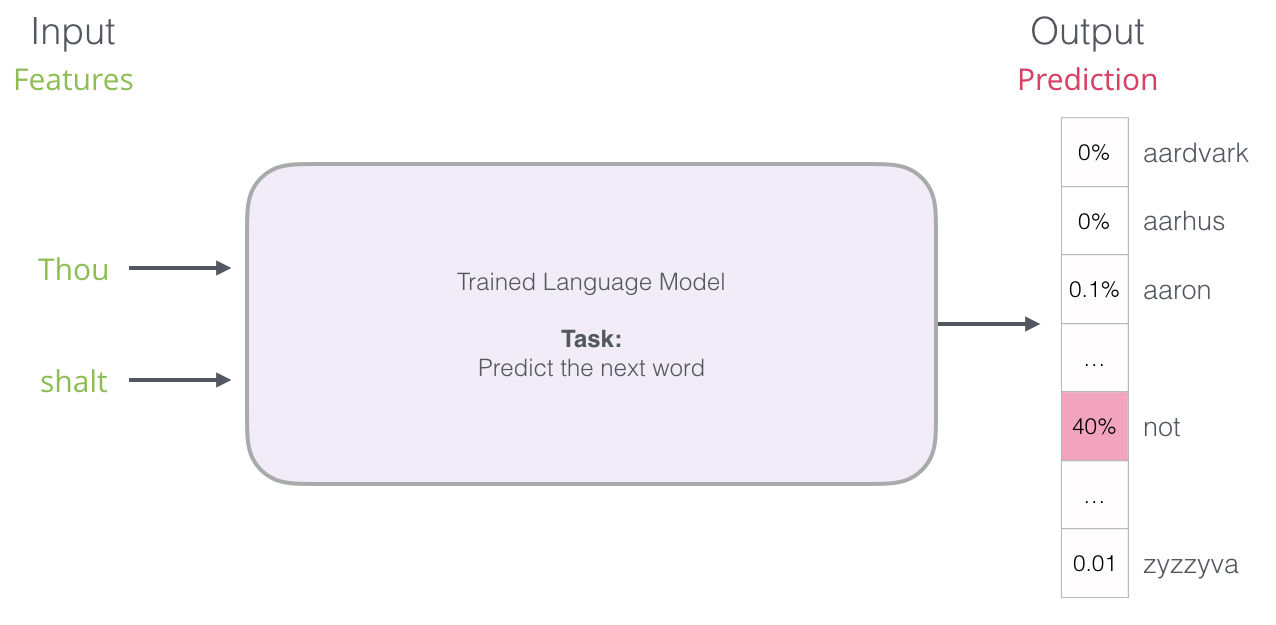
Después de ser entrenado, los primeros modelos de lenguaje (Bengio 2003) calculaban la predicción en tres pasos:
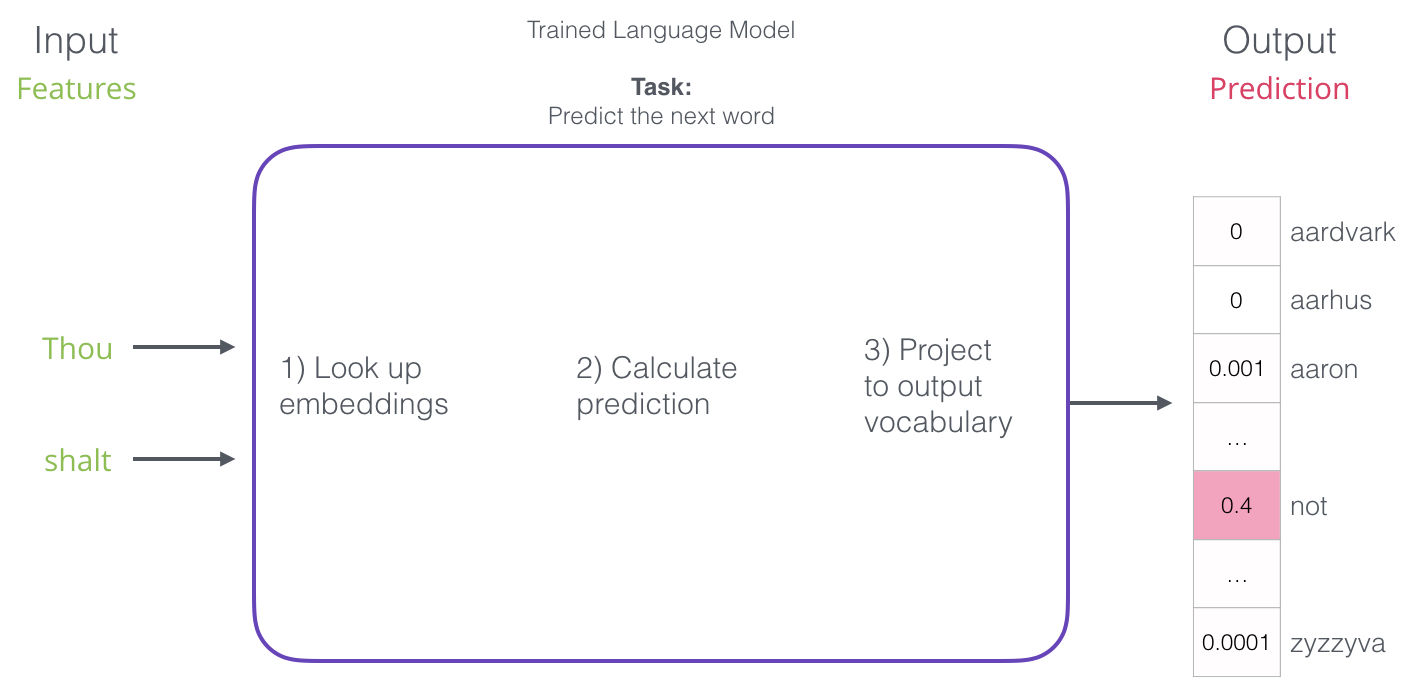
El primer paso es el más relevante para nosotros porque en este post estamos hablando sobre los embeddings. Uno de los resultados del proceso de entrenamiento es una matriz que contiene un embedding por cada uno de los tokens en nuestro vocabulario. Cuando estamos prediciendo, simplemente buscamos los embeddings de los tokens de entrad ay calculamos la predicción:
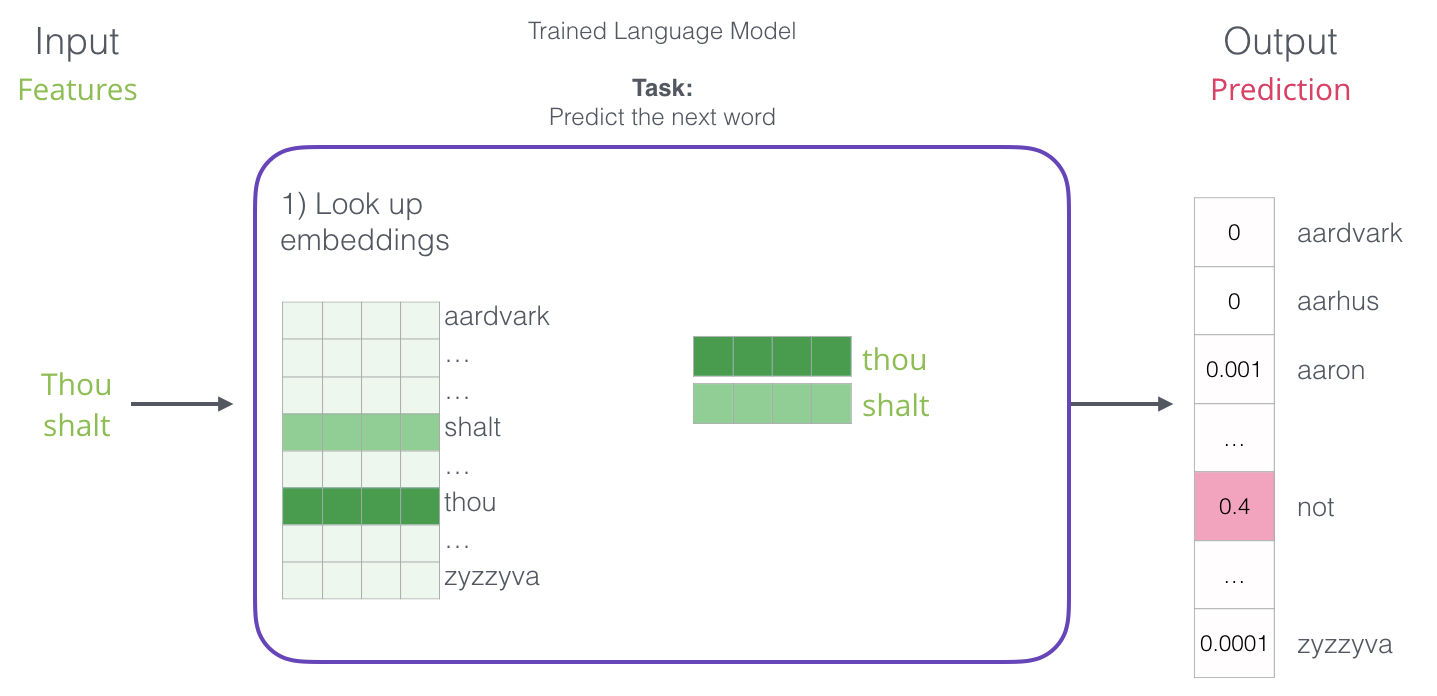
Ahora vamos a aprender cómo es que esta matriz de embeddings es creada.
Entrenamiento de modelos de lenguaje
“Un proceso no se puede entender deteniéndolo. La comprensión debe moverse con el flujo del proceso, debe unirse y fluir con él.” ~Dune
Los modelos de lenguaje tienen una gran ventaja sobre otros modelos de machine learning. Esa ventaja es que podemos entrenarlos usando texto – del cual tenemos mucho. Piensa en todos los libros, artículos, y otras formas de textos a nuestro al rededor. En contraste con otros modelos de aprendizaje automático que necesitan que la los datos sean preparados (y a veces obtenidos) específicamente para ellos.
“Conocerás una palabra por sus la compañía que mantiene alrededor” ~ J.R. Firth
Las palabras obtienen sus embeddings a partir de las palabras que aparecen a su alrededor. Esto funciona de la siguiente manera:
- Obtenemos un montón de texto (digamos, todos los artículos de Wikipedia), luego
- tomamos una ventana (digamos, de tres palabras) que movemos sobre todo el texto,
- Esta ventana genera nuestros ejemplos para el entrenamiento del modelo:
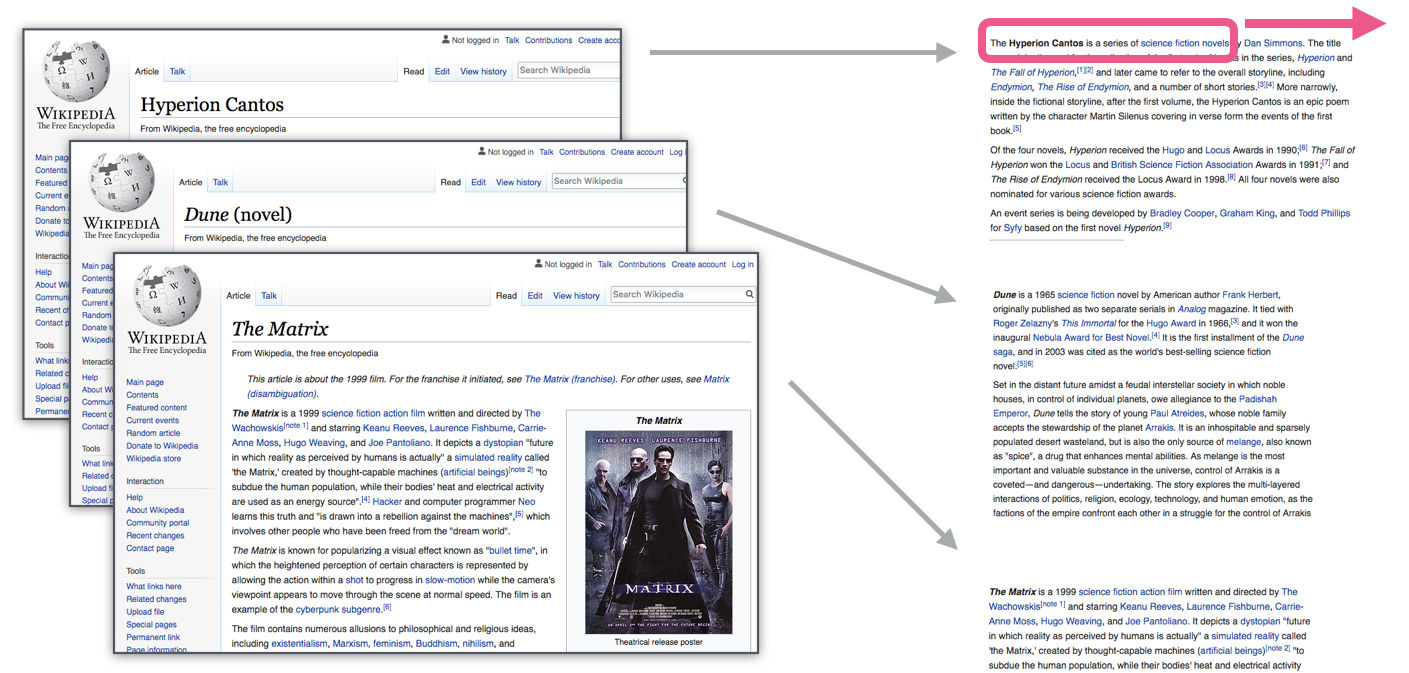
En tanto esta ventana se desliza, nosotros (virtualmente) generamos un dataset que usaremos para entrenar el modelo. Para ver cómo es que esto funciona, veamos cómo funciona el proceso para la siguiente frase:
“Thou shalt not make a machine in the likeness of a human mind” ~Dune
Cuando empezamos, la ventana está en las tres primeras palabras de la oración:

Tomamos las dos palabras como features, y la tercera como la etiqueta a predecir:

Luego entonces deslizamos la ventana a la siguiente posición para generar un segundo ejemplo de entrenamiento:
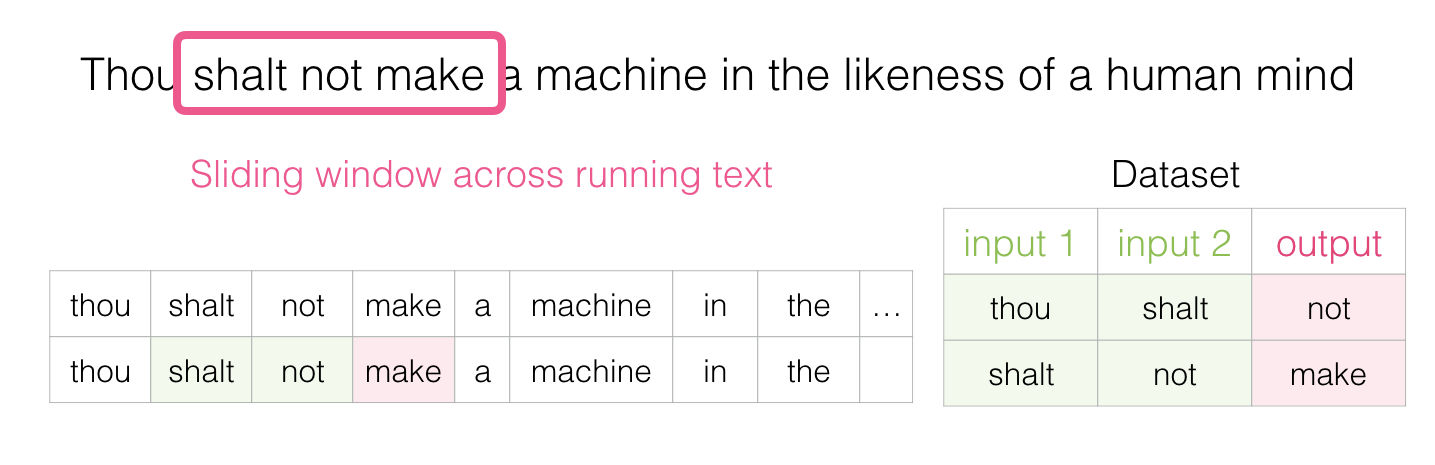
Y de pronto tendremos un gran dataset de palabras que suelen aparecer después de otro par:
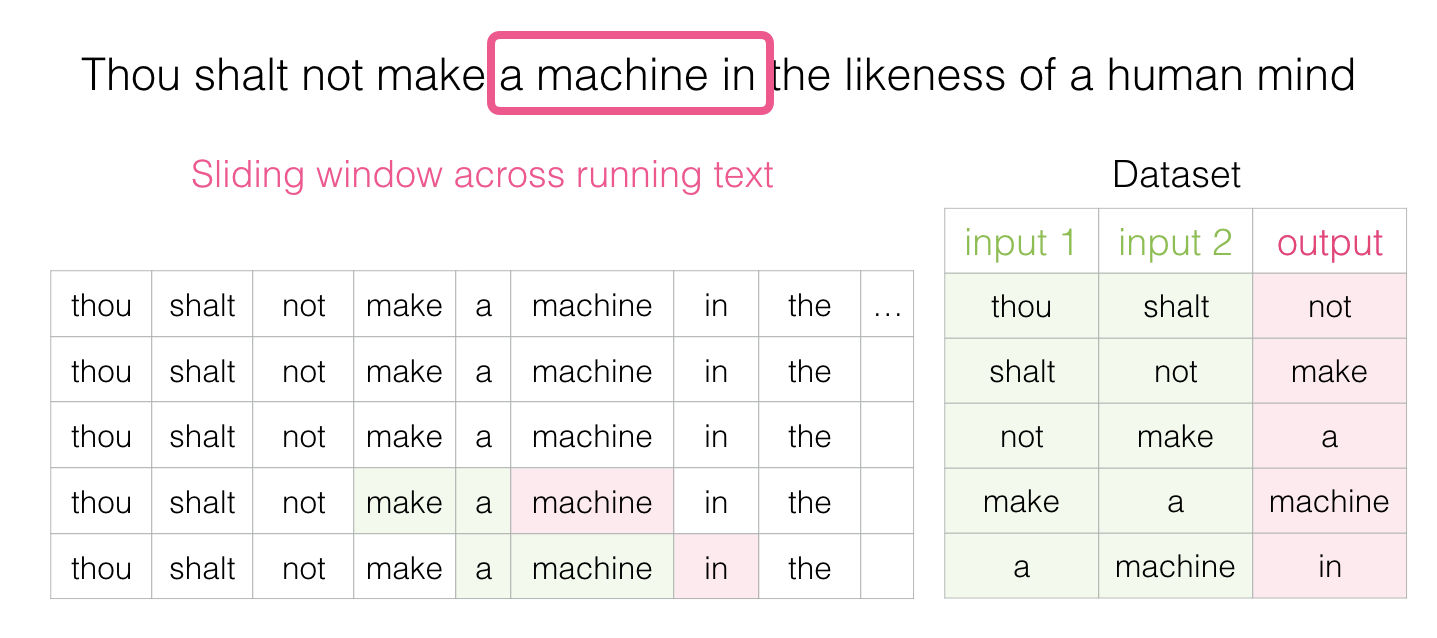
En la práctica, los modelos suelen ser entrenados mientras esta ventana se va deslizando, sin embargo, siento que es más claro separar lógicamente la etapa de generación del dataset de la etapa de entrenamiento. Además de modelos basados en redes neuronales, existe una técnica conocida como n-grams que es también usada comúnmente para entrenar modelos (mira el capítulo 3 de Speech and Language Processing). para ver cómo es que este cambio de n-grams a modelos neuronales se refleja en productos reales, revisa este post de Swiftkey mi teclado favorito para Android, introduciendo su modelo neuronal de lenguaje y comparándolo con su previo modelo basado en n-grams. me gusta este ejemplo porque muestra cómo las propiedades algorítmicas de los embeddings se pueden describir en lenguaje de marketing.
Mira hacia ambos lados
“La paradoja es un indicador que te dice que mires más allá. Si las paradojas te molestan, eso delata tu profundo deseo de absolutos. El relativista trata una paradoja simplemente como interesante, quizás divertida o incluso, un pensamiento terrible, educativo” ~ Dios emperador de Dune
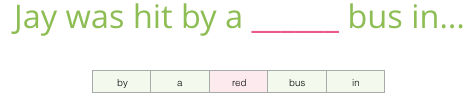
Sabiendo de lo que hablamos anteriormente en este post, completa la oración

El contexto que te he dado aquí son 5 palabras antes del espacio en blanco. Estoy seguro que la mayoría de las personas elegirían la palabra “bus” como solución. Pero qué sucedería si te doy un poco más de información – una palabra después del espacio en blanco, ¿cambiaría tu respuesta?
Esto cambia completamente lo que debería ir en el espacio en blanco, la palabra “red” es ahora la que tiene mayor sentido de ser elegida. Lo que hemos aprendido de esto es que tanto las palabras previas como las siguientes a una palabra determinada contienen un alto valor sobre esta palabra determinada. Resulta que tomar en cuenta ambas direcciones (palabras a la izquierda y derecha de la que estamos adivinando) nos lleva a tener mejor embeddings. Veamos cómo es que podemos tomar en cuenta esto al momento de entrenar nuestro modelo.
Skipgram
“La inteligencia se arriesga con datos limitados en un campo donde los errores no solo son posibles sino también necesarios.” ~Chapterhouse: Dune
En lugar de solamente mirar dos palabras antes de nuestra palabra objetivo, podemos también ver dos palabras después:
Si hacemos esto, el dataset que estamos construyendo virtualmente para entrenar el modelo se vería así:

Esta arquitectura es conocida como Continuous Bag of Words y es descrita en uno de los artículos de word2vec. Hay otra arquitectura que entregó grandes resultados haciendo las cosas un poco diferente.
El lugar de “adivinar” una palabra a partir de su contexto (las palabras antes y después de ella), esta otra arquitectura trata de predecir las palabras vecinas a partir de una palabra determinada. Podemos imaginar que la ventana se desliza sobre el texto de entrenamiento así:

Las casillas rosas están marcadas con diferentes tonalidades porque la ventana deslizante en realidad crea cuatro ejemplos diferentes en nuestro dataset:
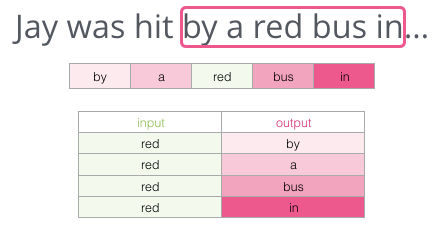
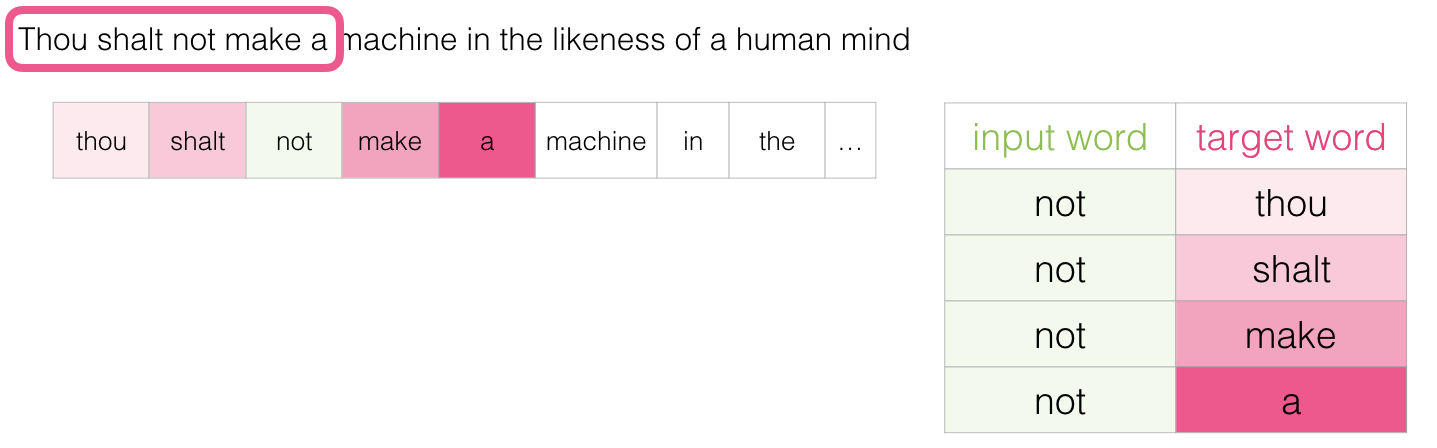
Este método es conocido como la arquitectura skipgram. Podemos visualizar la ventana deslizante haciendo algo así:

Esto añadiría cuatro ejemplos a nuestro dataset de entrenamiento:
Luego entonces podemos deslizar la ventana a su siguiente posición:
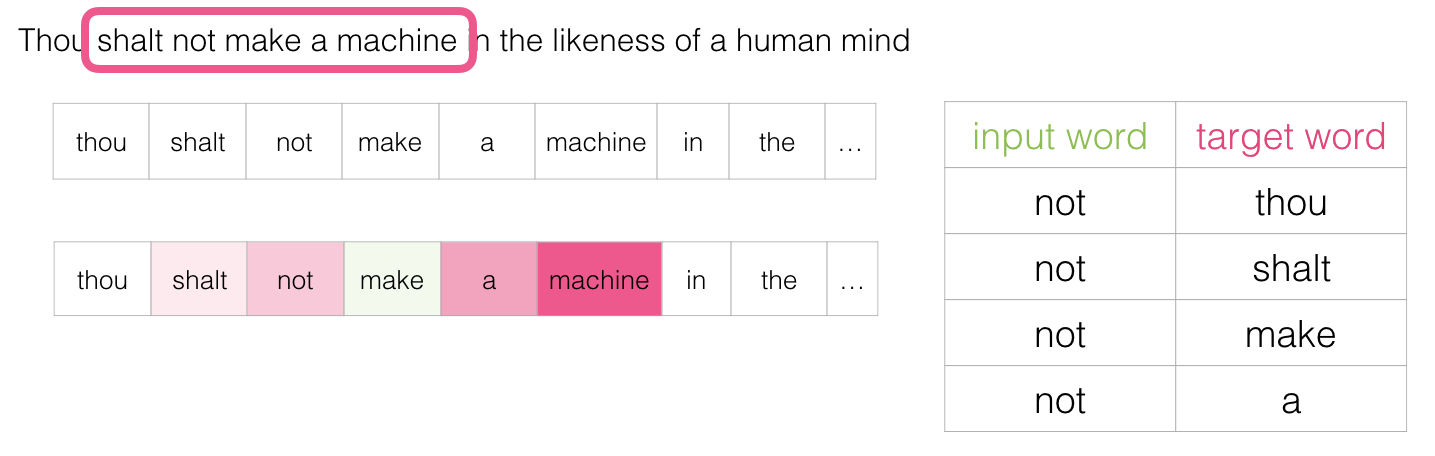
Esto genera otros cuatro ejemplos:

Un par de posiciones más adelante tenemos muchos más ejemplos:
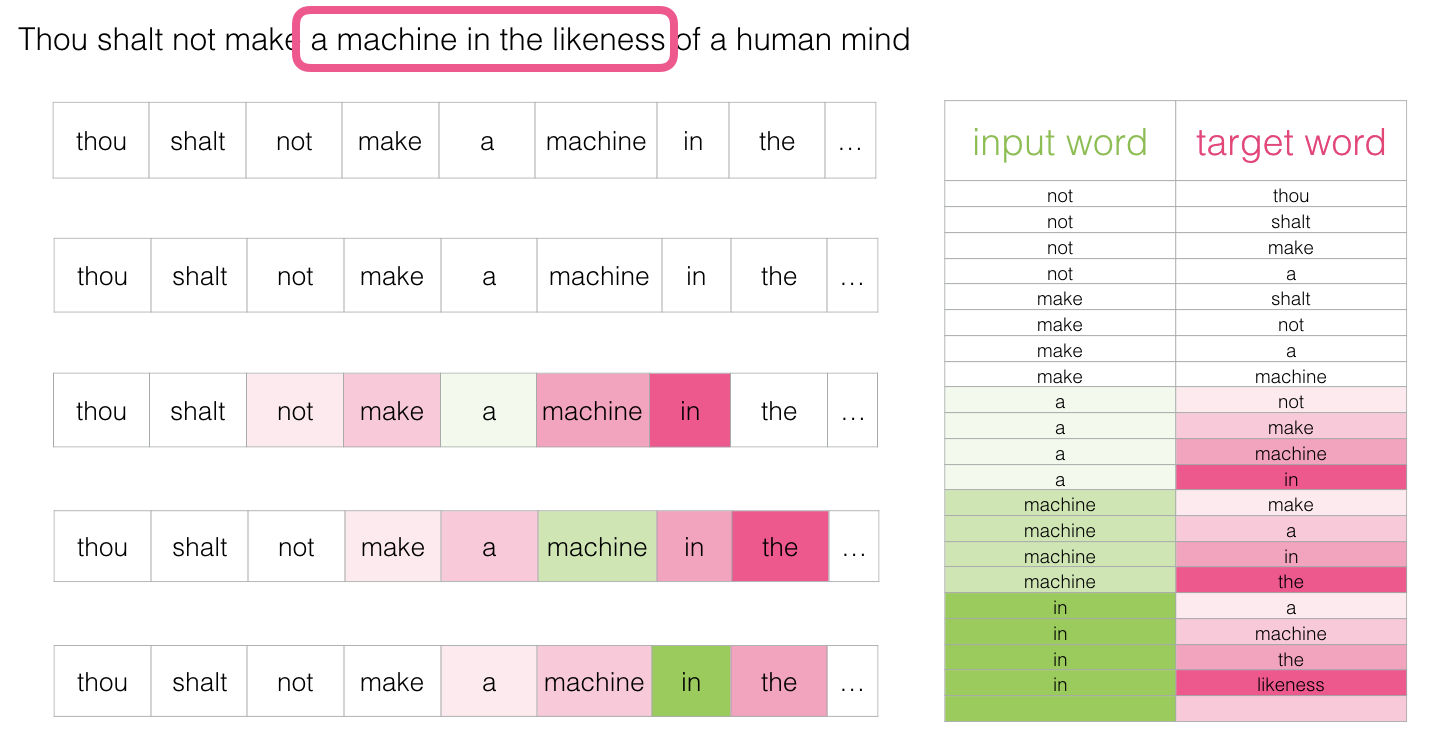
Revisando el proceso de entrenamiento
“Muad’Dib aprendió rápidamente porque su primer entrenamiento fue sobre cómo aprender. Y la primera lección de todas fue la confianza básica que podía aprender. Es impactante descubrir cuántas personas no creen que puedan aprender y cuántas más creen que aprender es difícil.” ~ Dune
Ahora que ya tenemos nuestro dataset creado a partir del modelo skipgram, echemos un vistazo a cómo lo podemos usar para entrenar un modelo neuronal básico de lenguaje que predice las palabras vecinas a otra.
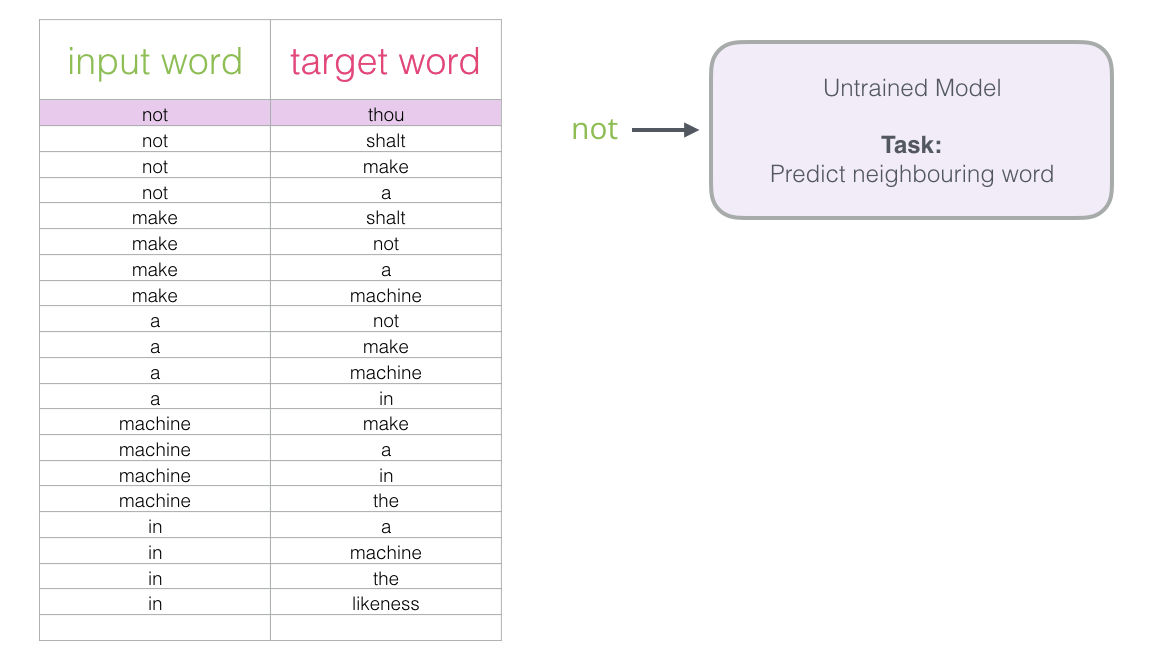
Comencemos por el primer ejemplo en nuestro dataset. Tomando la primer entrada y dándosela al modelo que aún no está entrenado pidiéndole su predicción para la siguiente palabra.
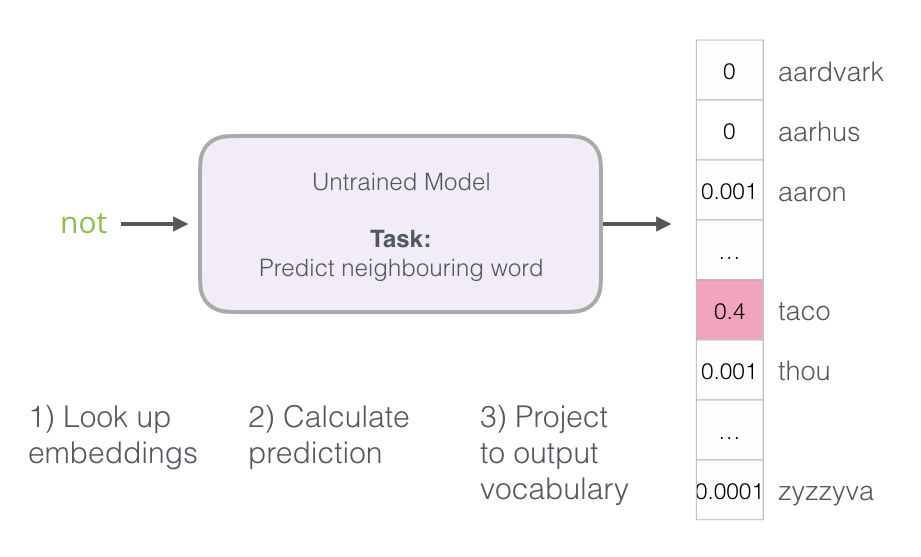
El modelo ejecuta los tres pasos definidos arriba y entrega un vector de predicción (en donde cada palabra en su vocabulario recibe una probabilidad). Dado que el modelo no está entrenado aún, sus predicciones son incorrectas en esta etapa; eso está bien. Nosotros sabemos qué palabra debió haber predicho – la palabra (o “etiqueta”) en la fila que estamos usando para entrenar el modelo:
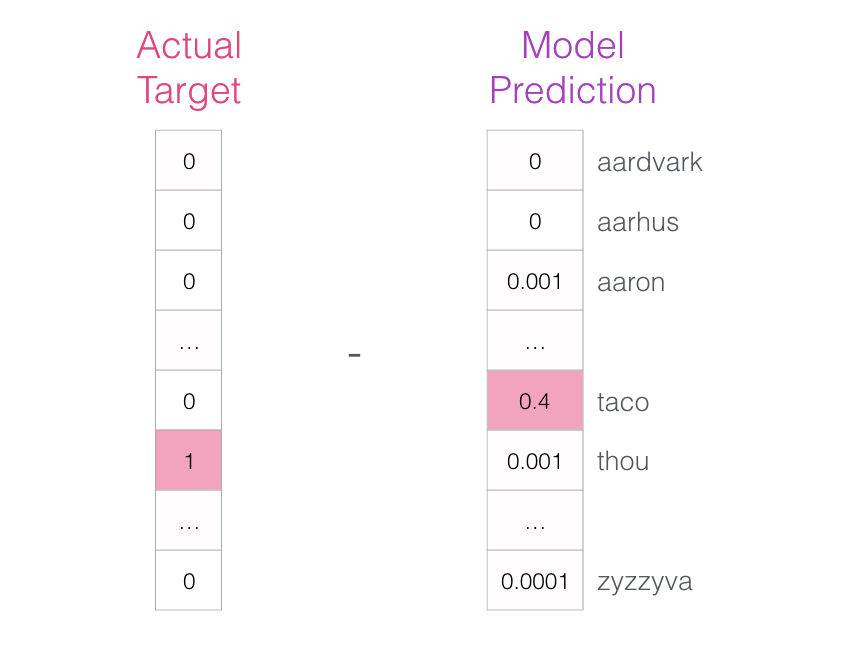
¿Qué tan lejos estuvo el modelo? para saber esto, restamos los dos vectores (el valor esperado menos el valor predecido) lo cual nos va a dar un vector “error”:
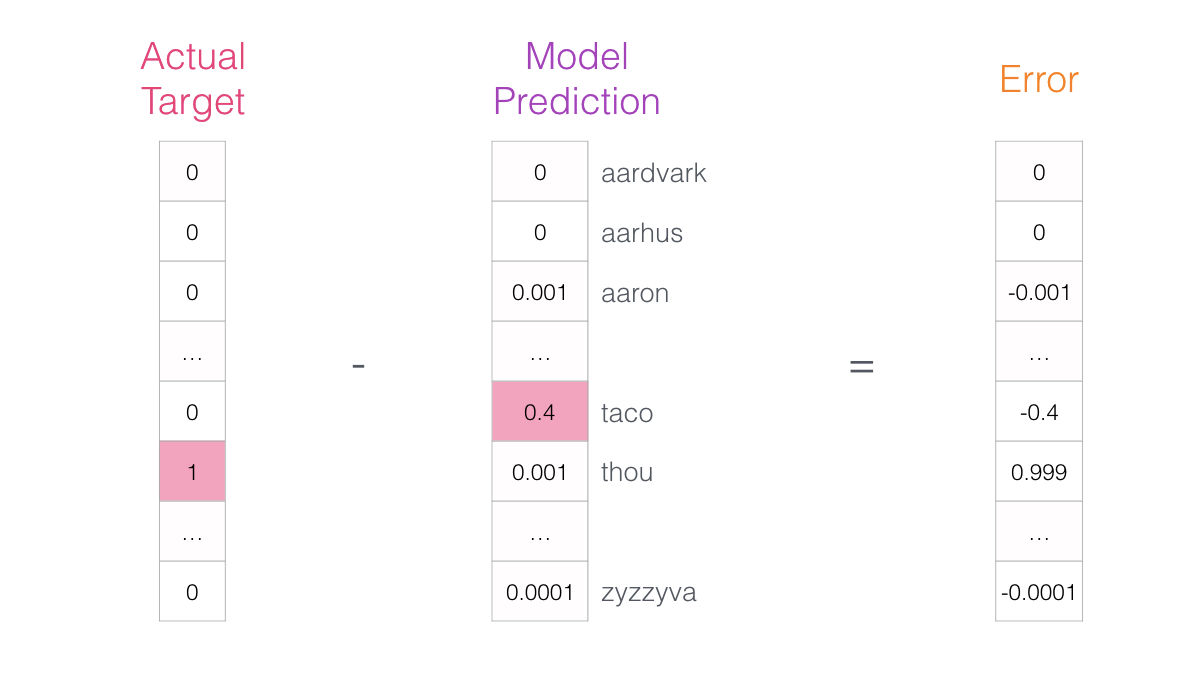
Este vector “error” puede ser usado para actualizar el modelo para que, la siguiente vez que se le pregunte, sea más probable que “adivine” thou cuando recibe not como entrada.
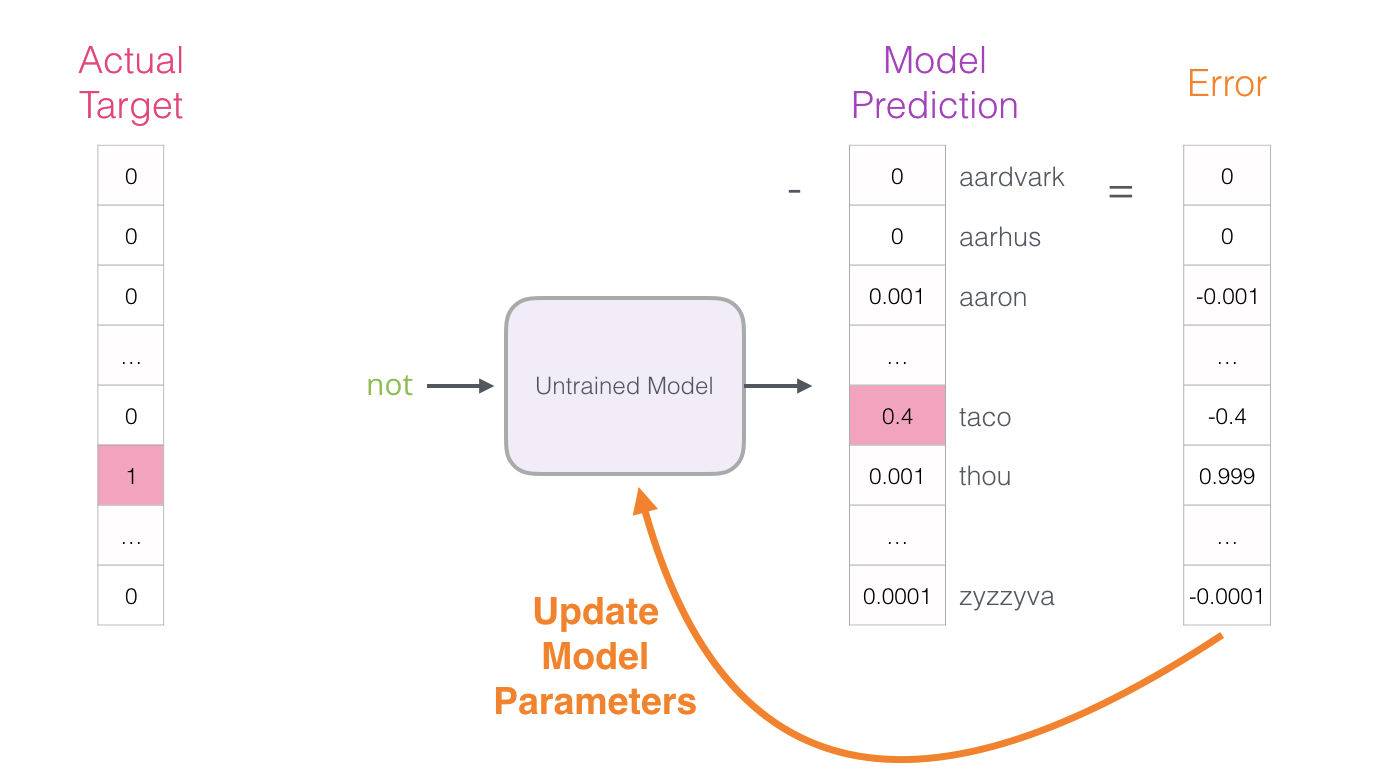
Y así concluye el primer paso del entrenamiento. Procedemos a ejecutar el mismo proceso con el siguiente ejemplo en nuestro dataset, y el siguiente, y el siguiente y así hasta que hayamos terminado de cubrir todos los ejemplos de nuestro dataset, con eso se cubre lo que en machine learning se conoce como una época de entrenamiento. Después repetimos el mismo proceso por un número de épocas y finalmente podemos extraer la matriz de embeddings (que son los parámetros internos de nuestro modelo neuronal) y usarla para cualquier otra aplicación.
Mientras qué hemos logrado entender el proceso, aún no llegamos a cómo es que word2vec fue entrenado en realidad. Nos faltan un par de ideas claves.
Sampleo negativo
“Intentar comprender a Muad’Dib sin comprender a sus enemigos mortales, los Harkonnen, es intentar ver la Verdad sin conocer la Falsedad. Es el intento de ver la Luz sin conocer la Oscuridad. No puede ser.” ~ Dune
Recordemos los tres pasos de cómo es que este modelo neuronal calcula su predicción:
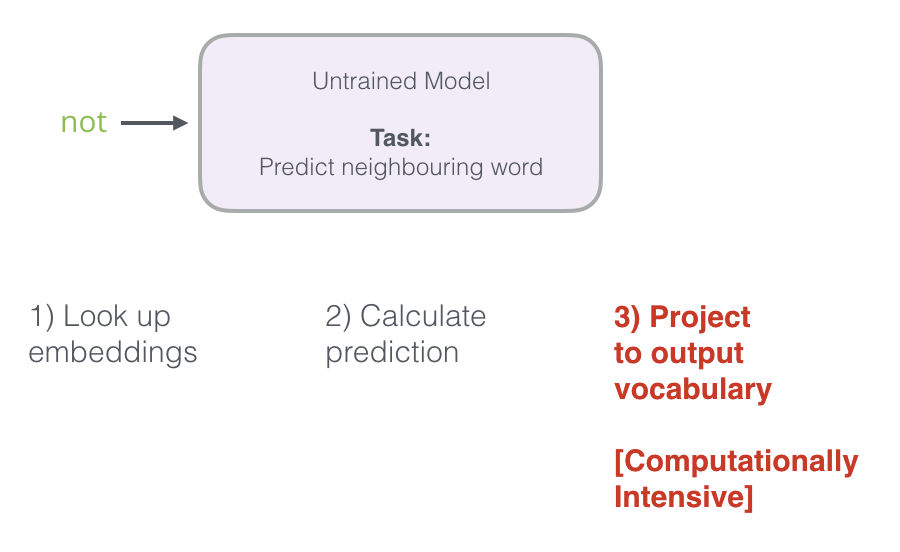
Este tercer paso es muy costoso desde un punto de vista computacional – especialmente sabiendo que tenemos que hacerlo una vez por cada ejemplo en nuestro dataset (que fácilmente será millones de veces). Necesitamos hacer algo para mejorar el desempeño.
Una forma de hacerlo es dividiendo nuestro objetivo en dos etapas:
- Generar embeddings de alta calidad (sin preocuparnos por predecir la siguiente palabra)
- Usar estos embeddings para entrenar un modelo de lenguaje (para ahora si, predecir la siguiente palabra)
Nos vamos a enfocar en el paso 1, ya que este post se trata de embeddings. Para generar unos de alta calidad mientras que usamos un modelo de alto desempeño podemos cambiar la funcionalidad del modelo de predecir la siguiente palabra:
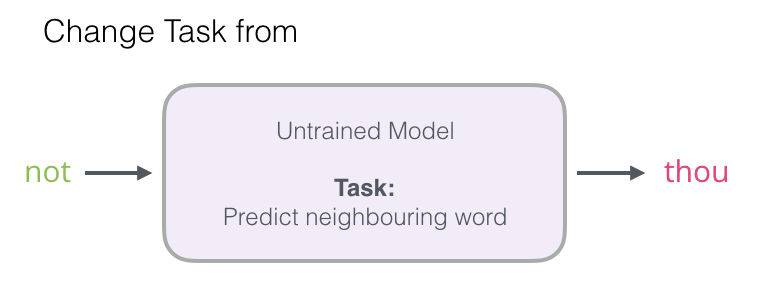
A uno que tome las dos palabras (la de entrada y la que sería de salida) y regrese una medida indicando si estas palabras son vecinas o no (0 para “no vecinas”, 1 para “vecinas”):

Este simple cambio también significa que podemos cambiar nuestro modelo de salidas de múltiples salidas a un modelo de regresión lineal – que se convierte en uno más sencillo y fácil de entrenar.
Este cambio también requiere que nosotros cambiemos la estructura de nuestro dataset – lo que era antes nuestra etiqueta ahora es otra entrada al modelo, y el valor a predecir es 0 o 1. Por ahora todos serán 1 puesto que todas nuestras palabras son “vecinas”.
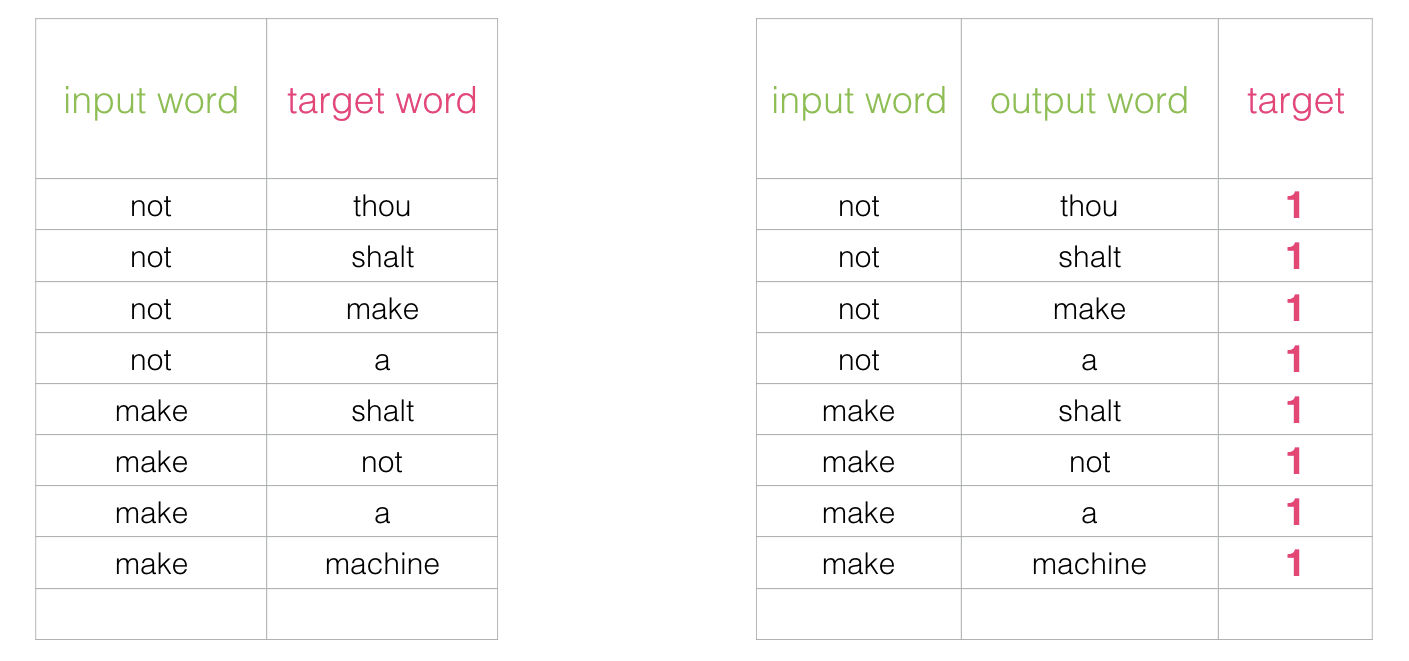
Este problema puede ser resuelto a una velocidad impresionante – procesando millones de ejemplos en minutos; sin embargo, existe un pequeño problema que debemos solucionar. Si todos nuestros ejemplos son positivos (es decir, etiqueta 1), nos estamos exponiendo a que nuestro modelo se pase de listillo y siempre regrese 1 como respuesta – logrando 100% de precisión pero sin aprender nada (y en el proceso generar embeddings que no sirven).
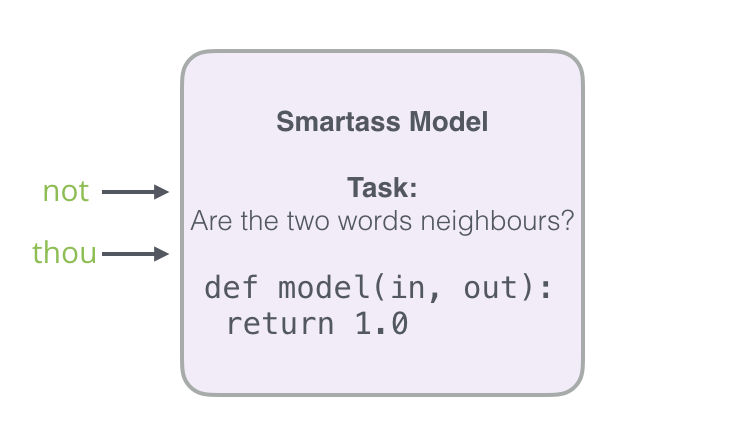
Para resolver esto, necesitamos incluir ejemplos negativos en nuestro dataset – ejemplos de palabras que no tienen relación y para las cuales nuestro modelo debe regresar 0 como predicción. Con eso tenemos ahora un verdadero reto para el cual nuestro modelo tiene que trabajar para resolver, sin embargo este proceso sigue siendo rápido.

Pero, ¿qué colocamos como palabras de “salida”? pues podemos elegir palabras de nuestro vocabulario aleatoriamente:
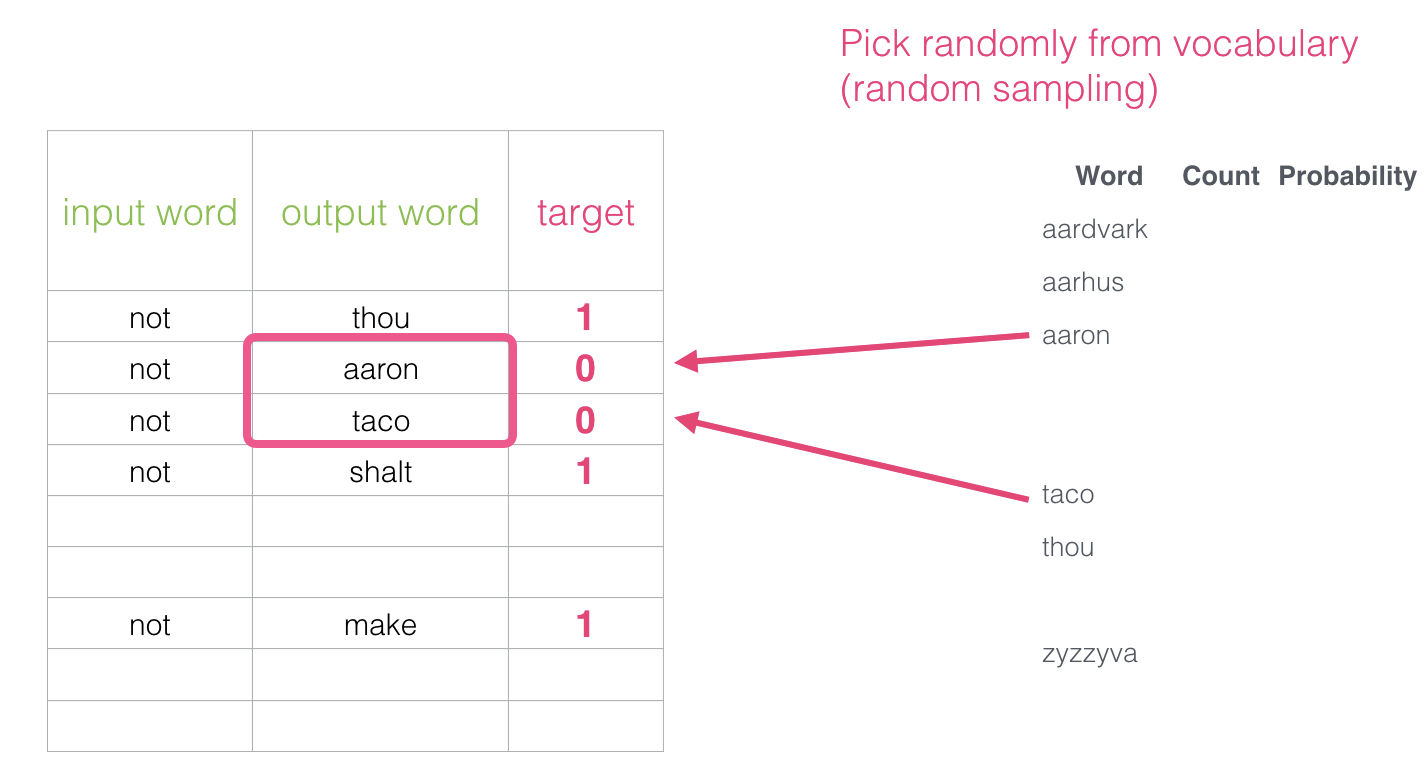
Esta idea está inspirada por noise-constrative estimation. Nosotros estamos contrastando la verdadera señal (los ejemplos positivos de palabras vecinas) con ruido (los ejemplos de palabras que no son vecinas elegidos aleatoriamente). Esto representa un excelente balance entre eficiencia computacional y estadística.
Skipgram con sampleo negativo
Ahora hemos cubierto dos de las ideas centrales en word2vec: en conjunto son llamadas skipgram con sampleo negativo (*Skipgram with Negative Sampling, SGNS)
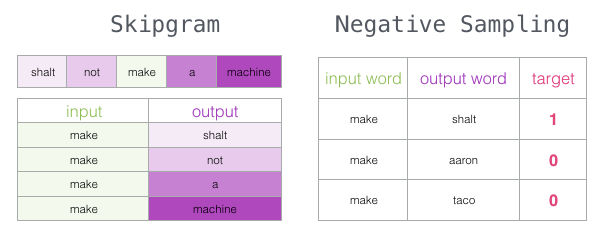
Proceso de entrenamiento de Word2vec
“La computadora no puede anticipar todos los problemas de importancia para los humanos. Es la diferencia entre bits en serie y un continuo ininterrumpido. Nosotros tenemos este; las máquinas se limitan al otro.” ~ Dune
Antes de que el proceso de entrenamiento comience, tenemos que pre-procesar el texto que vamos a usar para entrenar el modelo. Por ejemplo, determinamos el tamaño de nuestro vocabulario (llamaremos a este valor vocab_size, y digamos que su valor es 10,000) y qué palabras pertenecen a este.
Al principio de la face de entrenamiento creamos dos matrices – una de Embedding y otra de Contexto. Estas dos matrices tienen un vector (embedding) para cada palabra en el vocabulario, es decir vocab_size es el tamaño de una de sus dimensiones. La segunda dimensión es qué tan largo queremos que el embedding sea (llamemos a este parámetro embedding_size), 300 es un valor común, aunque anteriormente vimos un ejemplo de 50.
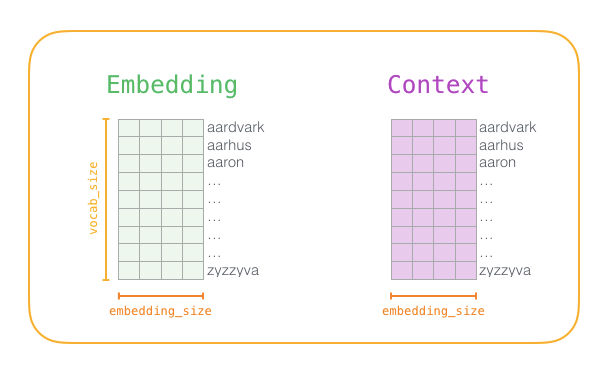
Cuando el proceso de entrenamiento comienza, rellenamos estas matrices con valores aleatorios. En cada paso de entrenamiento, tomamos un ejemplo positivo y su correspondiente negativo. Veámoslo con el primer grupo:
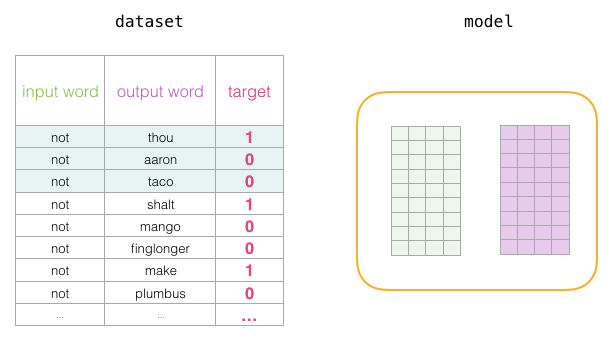
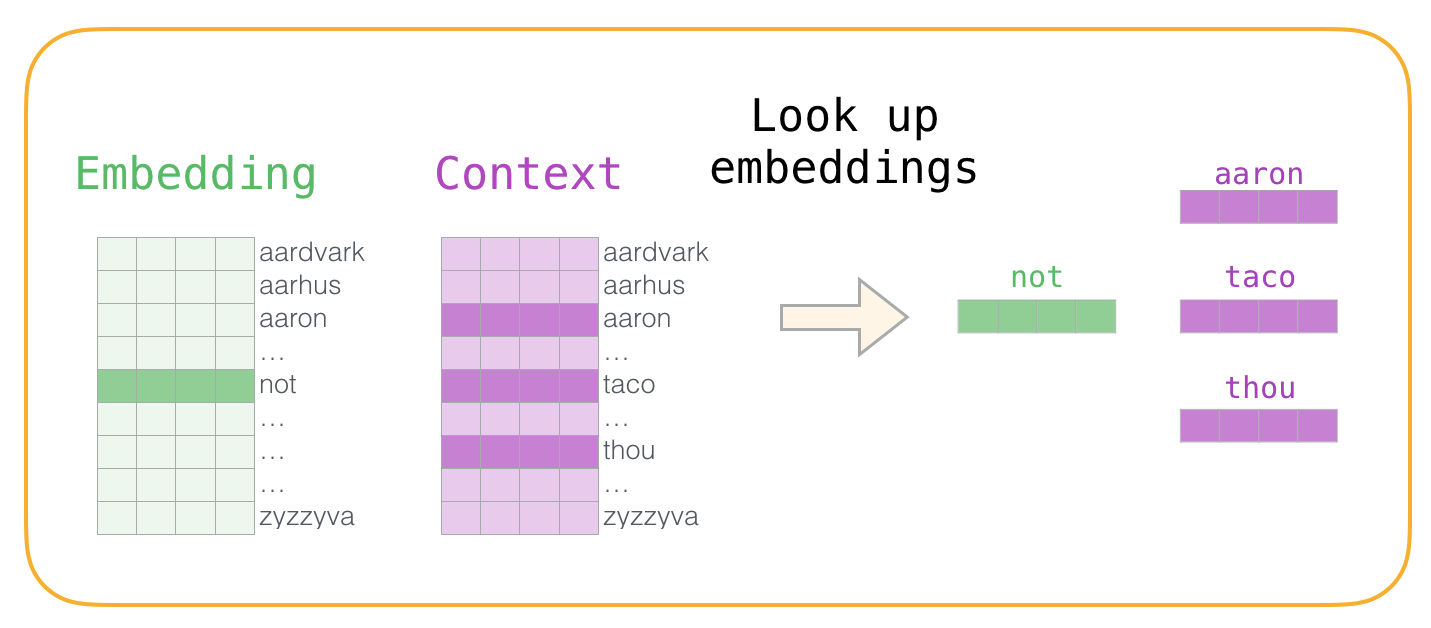
Ahora tenemos cuatro palabras: la de entrada not y la de salida o contexto thou (que es su vecina). Además, tenemos aaron y taco como ejemplos negativos. Con esto en mente, ubicamos sus embeddings: para la palabra de entrada, buscamos en la matriz Embedding mientras que para las palabras “contexto” los buscamos en la matriz Contexto (a pesar de que ambas matrices tienen un embedding para cada palabra en nuestro vocabulario).
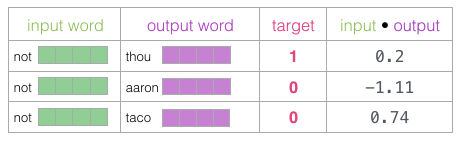
Después, tomamos el producto punto (dot product) del embedding de entrada con los embeddings contexto. En cada caso, este producto punto resultará en un número que indica la similtud entre estas dos palabras:
Necesitamos una forma de convertir estos valores en algo que parezca probabilidades – necesitamos que todas sean positivas y con valores entre 0 y 1. Este es un buen lugar para usar sigmoid.
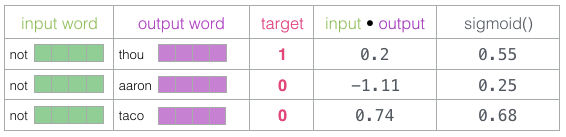
Ahora podemos tratar la salida de la operación sigmoid como la salida del modelo para estos ejemplos. Puedes ver que taco tiene el valor mayor mientras que aaron el menor, ambos antes y después de la operación sigmoid.
Una vez que el modelo no entrenado ha hecho una predicción, y sabiendo que tenemos un resultado correcto contra el cual comparar, vamos a calcular cuál fue el error en las predicciones del modelo. Para hacer eso, basta con restar los valores obtenidos de sigmoid contra el valor de salida verdadero (target):
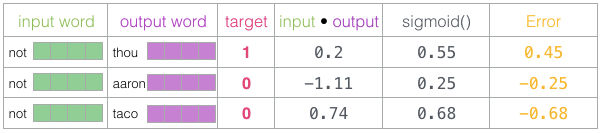
Aquí es donde viene la parte del learning en machine learning. Una vez que calculamos el error, podemos usarlo para ajustar los embeddings de nuestrass palabras, para que la próxima vez que necesitemos una predicción, los valores predecidos sean más parecidos a los valores esperados.

Con esto concluye un primer paso de entrenamiento. Una vez concluido, terminamos con embeddings un poquito mejores para las palabras involucradas en él (not, thou, aaron y taco). Ahora si, podemos pasar al siguiente paso, es decir, el siguiente ejemplo positivo y sus correspondientes negativos para ejecutar el proceso nuevamente.
Los embeddings seguirán mejorando mientras iteramos sobre todo nuestro dataset. En cualquier momento podemos detener el proceso de entrenamiento, descartar la matriz Contexto y usar los embeddings en la matriz Embedding para cualquier otra tarea.
Tamaño de ventana y número de ejemplos negativos
Hay dos híper parámetros claves en el proceso de entrenamiento de word2vec, estos son el tamaño de la ventana y el número de ejemplos negativos.
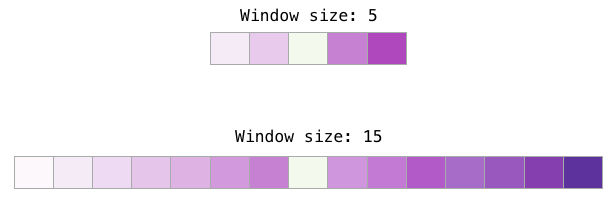
Diferentes tareas se benefician de diferentes tamaños de ventana. Una heurística que podemos emplear es que tamaños de ventana pequeños (2-15) llevan a embeddings donde altos valores de similitud indican que las palabras son intercambiables (toma en cuenta que los antónimos suelen ser intercambiables si solo nos fijamos en las palabras que los rodean – por ejemplo, “bueno” y “malo” suelen aparecer en contextos similares). Los tamaños de ventana más grandes nos llevana a embeddings en donde la similitud es más bien una medida del nivel de relación entre dos palabras. En la práctica, probablemente tengas que proveer anotaciones que guíen el proceso de generación de embeddings y entreguen un sentido mejor de similitud. El tamaño de ventana por default en Gensim es 5 (dos palabras antes y dos palabras después de la palabra de entrada).
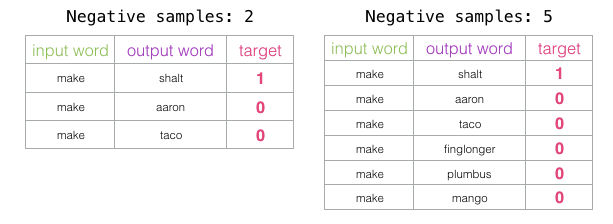
El número de ejemplos negativos es otro factor a considerar en el proceso de entrenamiento, el paper original recomienda de 5 a 20 como un buen número de ejemplos negativos. También menciona que de 2 a 5 suele ser suficiente cuando se tiene un dataset de buen tamaño. El default en Gensim es 5 ejemplos negativos.
Conclusión
“Si sale de tu dominio, entonces estás interactuando con inteligencia, no con automatización.” ~ Dios Emperador de Dune
Espero que ahora ya comprendas qué son los embeddings y el algoritmo detrás de word2vec. También espero que cuando leas un artículo científico mencionando “skipgram with negative sampling” (como los que mencioné al principio), entiendas lo que significan estos conceptos. Como siempre, cualquier comentario es bien apreciado @JayAlammar
Referencias y recursos para seguir leyendo
- Distributed Representations of Words and Phrases and their Compositionality [pdf]
- Efficient Estimation of Word Representations in Vector Space [pdf]
- A Neural Probabilistic Language Model [pdf]
- Speech and Language Processing by Dan Jurafsky and James H. Martin is a leading resource for NLP. Word2vec is tackled in Chapter 6.
- Neural Network Methods in Natural Language Processing by Yoav Goldberg is a great read for neural NLP topics.
- Chris McCormick has written some great blog posts about Word2vec. He also just released The Inner Workings of word2vec, an E-book focused on the internals of word2vec.
- Want to read the code? Here are two options:
- Gensim’s python implementation of word2vec
- Mikolov’s original implementation in C — better yet, this version with detailed comments from Chris McCormick.
- Evaluating distributional models of compositional semantics
- On word embeddings, part 2
- Dune
Sin más les recuerdo que como siempre, quedo atento a sus dudas y comentarios en mi cuenta de Twitter @feregri_no, en donde me pueden con contactar para hablar sobre ciencia de datos, ingeniería de software y muchas cosas más.
